
April 22, 2025
Some Experiments into How Google's Crawler works
Why experiment with Googlebot Beyond the fact it is interesting to understand how it works, it is potential useful if you ca...
Expert insights, guides, and tips to improve your website's SEO performance

The rise of AI, rather than search, crawlers visiting websites and "indexing" information is a controversial topic in SEO circles but something that perhaps we need to get used to. Citing the source information is something that AI providers, although apparently somewhat reluctantly, do seem to be working on.
For Google Search there is an implicit agreement to the crawling where we allow them to crawl our site, use our content, in return for the possibility to gain traffic. This implied agreement is arguably in trouble with Google's pushing of AIO and AI mode, but it is the case. With AI it is hard to make that agreement because they don't send the same level of traffic and because by design they're not really intended to.
Still, you might want that chance of traffic. If AI is going to talk about your subject regardless of what you do and people are asking AI things. Then it's better to have a chance of a citation than no chance at all.
Recently I was looking into llms.txt . This is a file that you put in the root directory of your site. You write it in a markdown format and it essentially helps AI understand what information is available. In ours we simply put the meta description for the page and the link. It should be in a very specific format that is in the specification. You can also add an llms-full.txt with more detailed information.
For us this was mostly a learning exercise rather than anything of practical use. Be once it's made, we may as well list it somewhere. Enter llmstxt.site , a directory of sites that have llms.txt files. For some reason it's not the most authoritative site in the world, but it does happen to also be a free link.
Adding your site to the directory is quite a process though. Perhaps barriers to entry a good thing or what would be the point? But it does take some knowledge and a github account. Go to the github repository and fork it (you'll need a github account, click the fork button at the top right). This gives you your own copy to work on that you can find by clicking your username at the top left and then clicking it in the repositories.
You'll be in the site code but your copy of it. You can double check this by looking at the top where there'll be a little line that says "forked from".
Click on data.json, click the pencil icon at the top right to "edit this file" and carefully add json for your site that says where it can find the llms.txt. For example, we would enter:
{
"product": "The Crawl Tool",
"website": "https://www.thecrawltool.com/",
"llms-full-txt": "https://www.thecrawltool.com/llms-full.txt",
"llms-full-txt-tokens": null,
"llms-txt": "https://www.thecrawltool.com/llms.txt",
"llms-txt-tokens": null
},
Keep it tidy and follow the format in the file. It's a good idea to copy and paste the entire json into an online json tester. Save it.
Once you're done, go to https://github.com/krish-adi/llmstxt-site/ . You now need to create a "pull request", which asks the originally owner to incorporate your changes into the actual site. Rather than me rewriting how to do that - here are the github instructions.
Now wait....3 weeks in our case! With a bit of luck your request will be merged (accepted) and entered into the code. A while after that it will start to show on the site.
Here we can only say what happened for us - but hopefully yours will have the same effect. Shortly after that we saw activity from Anthropic's crawler.
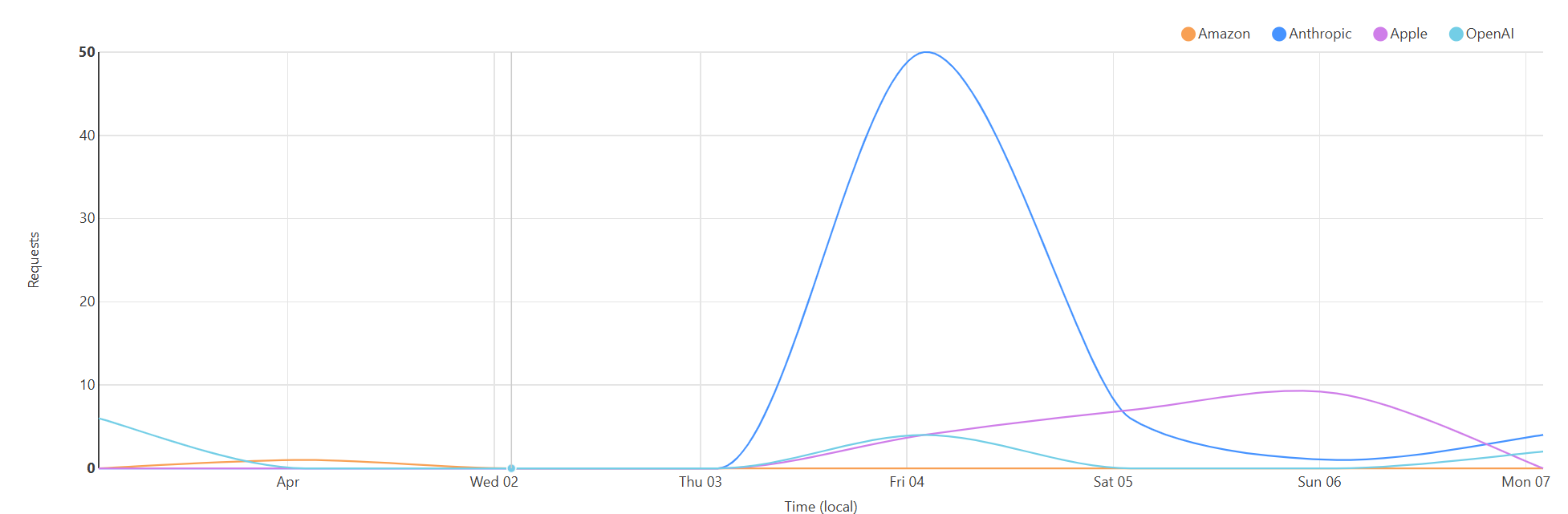
And by "shortly" we mean the same day. We're a small, but rapidly growing site and SEO tool, so that activity is virtually all of our public pages. OpenAI it seems, doesn't care at all!
Well no, to be honest it's pretty unclear what it means other than that Anthropic have gathered the data. If I ask then most AIs tell me their training data cuts off somewhere in 2023 or early 2024. That's some time ago. But most AI providers are clearly doing something or other that can ingest additional data when relevant to be able to answer questions outside of that data set. llms.txt seems good for that, but if I ask something like Claude questions then this data clearly isn't in its results or considered.
There's a possibility that it's just some test set, or it'll show up in data in the future. All we can tell is that we opened the door and offered information, and it was taken. The AI world seems to work on a much slower time scale then traditional search.
The question for you, of course, is - is it worth opening the door now for possible later benefits?
Start with a free crawl of up to 1,000 URLs and get actionable insights today.
Try The Crawl Tool Free
Why experiment with Googlebot Beyond the fact it is interesting to understand how it works, it is potential useful if you ca...

LLMS.TXT again I've written about LLMS.TXT in the article about how getting one listed in an llms.txt directory mysteriously...

What's this about Adding Other Media to robots.txt I recently came across John Mueller's (a Google Search advocate) blog. I ...

Understanding the Importance of having a fast Mobile website I, personally, spend a lot of time focusing on site speed. The ...
What are robots.txt, sitemap.xml, and llms.txt These files are used by search engines and bots to discover content and to le...

AI Crawlers and Citing Sources The rise of AI, rather than search, crawlers visiting websites and "indexing" information is ...