
April 22, 2025
Some Experiments into How Google's Crawler works
Why experiment with Googlebot Beyond the fact it is interesting to understand how it works, it is potential useful if you ca...
Expert insights, guides, and tips to improve your website's SEO performance

I recently came across John Mueller's (a Google Search advocate) blog. I initially considered not reading it. In this article I talk about how he connected the idea of AI feature images with low effort and that then he knows he can ignore the content. While his blog shows zero feature images whatsoever and the social tags just show a low effort screenshot from within the article. That's less effort than the AI images! But I'm glad I didn't follow his advice, and read it anyway! I was interested in this post:
Embedding robots.txt in WAV files
It was cool in a tech geek way, interesting, but also worrying. Because it's cool in a tech geek way I'm going to completely ignore why we would want to serve wav files to bots that don't listen to them. Coz, you know, we're tech geeks.
I read the article with a mix of fascination and growing concern. The SEO industry has shifted over the years to the point where there are a few people who actively put out information from Google, where what they say often conflicts with itself, and it is largely blindly followed. John Mueller is one of those people. It looks like his personal blog, but when someone speaks from such a position there's a certain responsibility, a certain requirement for accuracy, and a certain need for an understanding that people will follow you in doing it.
Whilst adding other media, in this case a wav file, to robots.txt is a super cool and geeky thing to do. It's also a very stupid thing to do and doesn't follow the standards as claimed. Yet it is presented in a way and by a person where it will encourage others to try it.
He leads with this:
The robots.txt standard has a nifty feature: it will ignore anything that it doesn’t understand. Random text, ASCII art, and even other data can be added without making the robots.txt file invalid.
He linked the robots exclusion protocol. But read it - it says absolutely nothing about ignoring anything it doesn't understand! We see this a lot in the SEO field - connecting to an authority as an argument for something. But that authority doesn't say what it is claimed it does. Sometimes that's deliberate, sometimes (like I suspect here) it's you think something, so you link to it intending to be helpful but haven't actually checked it yourself. That's very unfortunate because in this case it makes the reader think that everything that John talks about in the implementation of this is standards compliant - when the opposite is true. If you read it you'll find it doesn't mention that it should "ignore anything that it doesn't understand". It does say a couple of somewhat related things. The only specific "ignore" in the standard is this:
The crawler SHOULD ignore "disallow" and "allow" rules that are not in any group (for example, any rule that precedes the first user-agent line).
So if disallow or allow rules can't be associated with a user-agent to disallow and allow for then they should be ignored. That makes sense because the only other choice is to assume the author meant to apply it to every user agent, which may not have been the intent.
That's it - that is the single ignore.
Now I am being a little one sided in the argument here. Because the standard does set out the expected format of the robots.txt, and that includes UTF-8 characters. It just doesn't mention what to do if they are not UTF-8 characters except in the specific circumstance of Allow and Disallow with non UTF-8 characters in where a parser can make a choice.
Implementors MAY bridge encoding mismatches if they detect that the robots.txt file is not UTF-8 encoded.
Which we can reason is because of the increased probability that binary characters might occur in the path if the robots.txt is programmatically generated. However, it seems that the expectation is largely that non UTF-8 characters do not occur because of this:
The rules MUST be accessible in a file named "/robots.txt" (all lowercase) in the top-level path of the service. The file MUST be UTF-8 encoded (as defined in [RFC3629]) and Internet Media Type "text/plain" (as defined in [RFC2046]).
If a valid, standards compliant, robots.txt file must consist of UTF-8 encoded plain text data then it's never going to come across binary to ignore! So they can probably be forgiven for not making any mention on ignoring it more generally!
In the context of this required UTF-8 plain text file, far from ignoring the crawler must parse every line that is parseable.
Crawlers MUST try to parse each line of the robots.txt file. Crawlers MUST use the parseable rules
It's tempting to expand that out to it must ignore every line that is not parseable, but that's not what it says.
Crawlers MAY interpret other records that are not part of the robots.txt protocol -- for example, "Sitemaps"
The protocol is subject to expansion. So a piece of text that produces something in one parser may not produce something in another. A piece of text that produces no behaviour today, may produce behaviour in the future. So you can't ignore it, you still parse it.
We can re-enforce this interpretation with the fact that the standard defines how to write a comment. i.e. something to be specifically ignored in parsing!
It's a cool trick, but whilst it is very heavily implied that it is standards compliant - anybody reading the standard can see that just isn't true.
John gives a text example that you could do something like:
Roses are red Violets are blue user-agent: Googlebot disallow: /foo
And you can with Google's parser - you can try this on The Crawl Tool if you go to the titles report, select the robots.txt button, and fill in the text field:
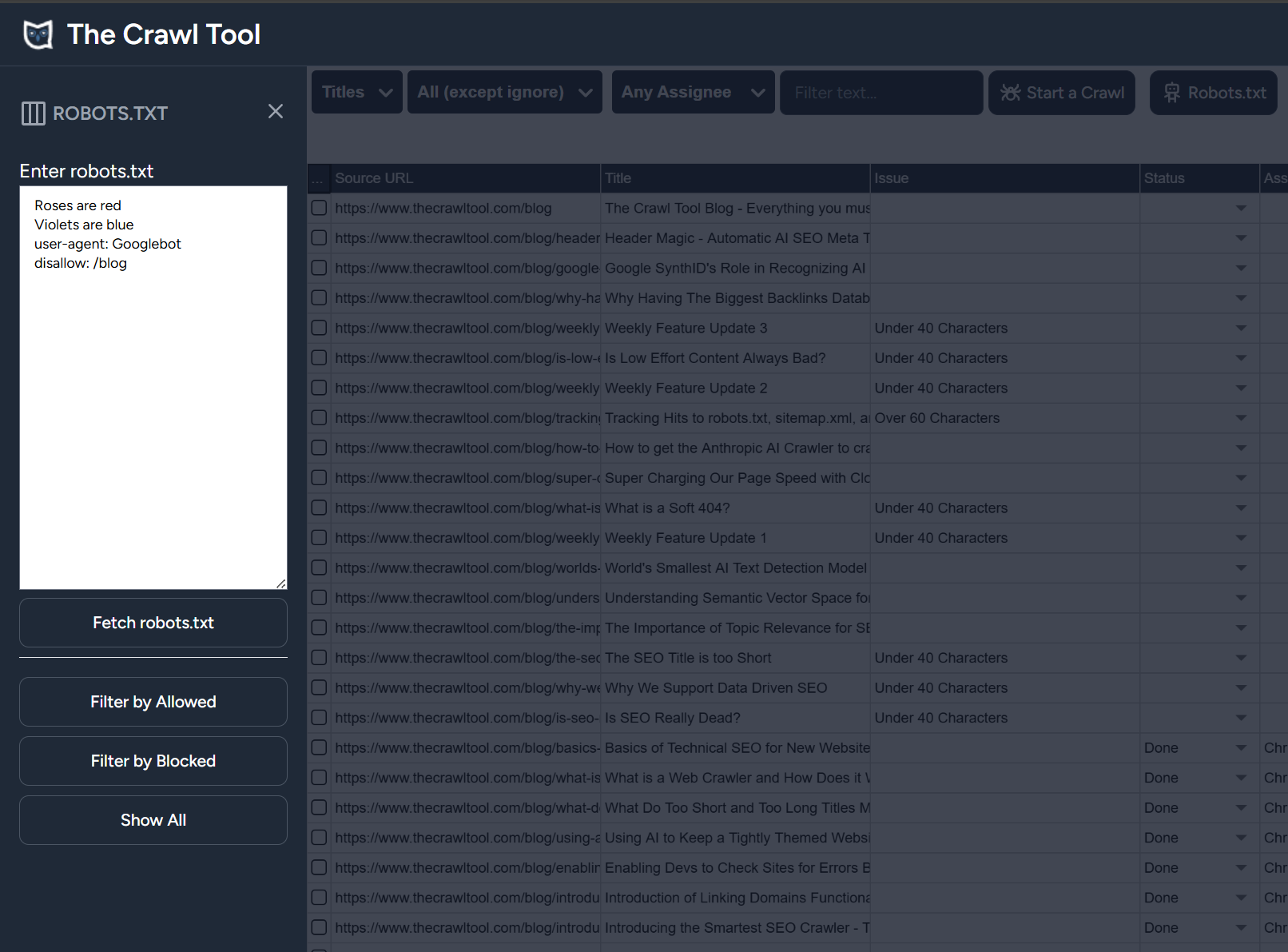
You can also try moving the disallow: line before the user-agent and you will see that it doesn't apply.
But it's not really true that "Roses are red" and "Violets are blue" aren't parsed. They just produce no behaviour currently and in Google's robots.txt parser. That behaviour could change in the future or in other parsers. It's unlikely because of the example choice, but it's very important to understand.
If I write it like this though:
# Roses are red # Violets are blue user-agent: Googlebot disallow: /blog
Then it is always considered a comment and the behaviour should be consistent and never change. Fill that in and try it and you'll find that also works.
Now most of us can't imagine "roses are red" and "violets are blue" ever being attached to some kind of behaviour and the example is chosen to that extreme. In this sort of case I like to take the opposite extreme and see what happens so that we've tested the edge cases. Let's write a different poem about robots.txt files:
Roses are red user-agent: Googlebot disallow: / Don't do this you clot. user-agent: Googlebot disallow: /blog
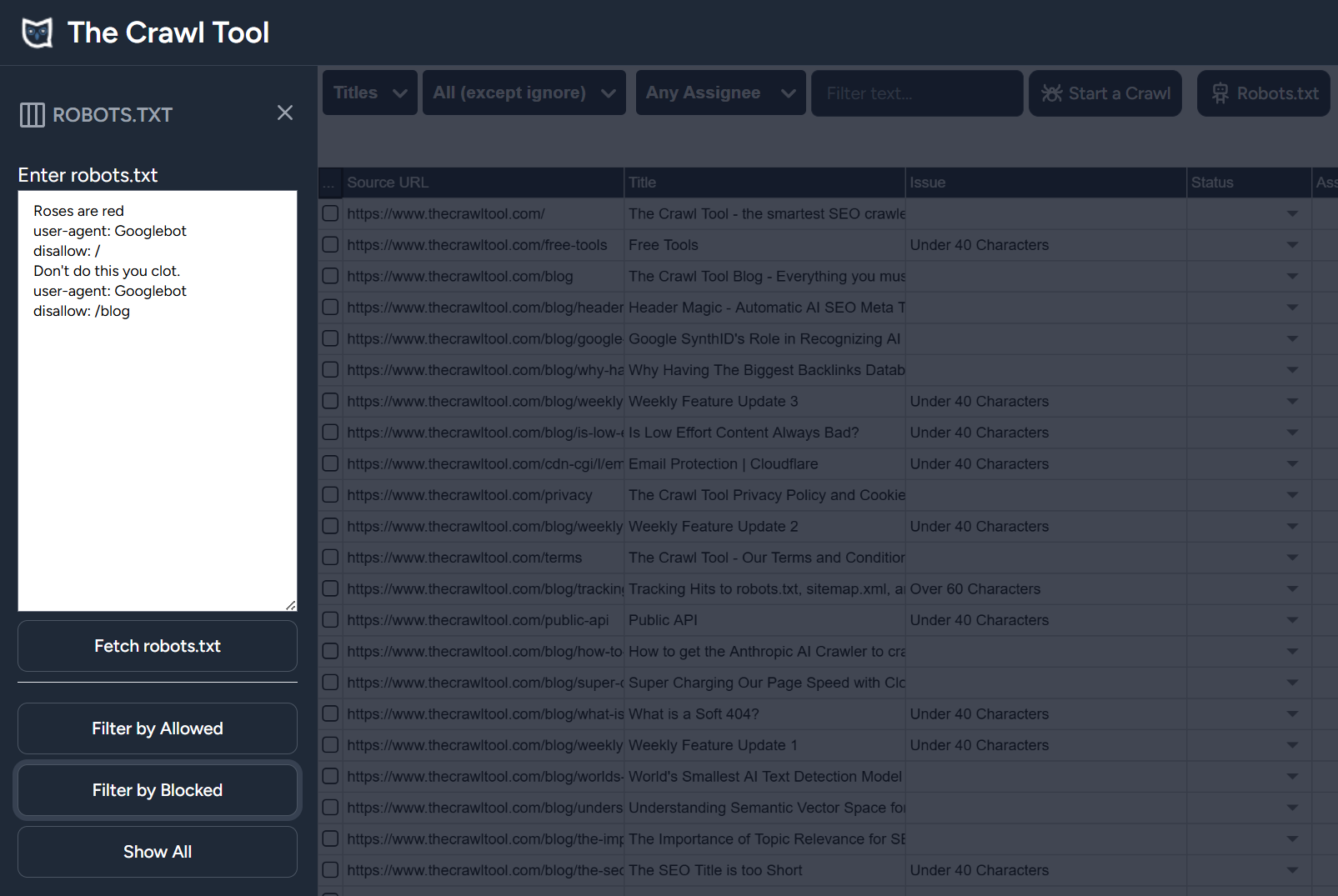
This blocks everything, rather than just the /blog posts we'd intended. Let's not make this any longer by showing it but if you put your poem in as comments with # then it has the intended behaviour.
Neither is, of course, a likely real world example. The truth is somewhere in between. But hopefully the point here is that what John describes is not standards compliant and the risk of that is changing and unexpected behavior.
Another way of saying this is when we write "Roses are red" or something similar then Google's parser is actually running them as any regular rule. It's just they do nothing - for now. But it is not a "nifty feature" of the robots.txt standard that they're ignored. Quite the opposite. It's a rule of the standard that they "must try to parse them".
He moves on to wav files. This is a clever technique called injection. It is essentially putting one content type where it doesn't belong, and wasn't intended. It's often used by hacking exploits.
This can work because stuff that is producing no behaviour surrounds stuff that does. Remember the standard does say that the parser should parse the file line by line. If the file isn't the compliant required UTF-8 plaint text file then it gets somewhat unclear for a parser where lines begin and end.
For the robots.txt file, start with a comment line ("# comment…"). Otherwise, any initial directive you might have could be broken by binary data that comes before it. Starting with a comment line in robots.txt is a good practice anyway, it makes sure that any extra UTF-8 BOMs don’t break the first line. Similarly, I like to close with a comment line so that binary data afterwards doesn’t get seen as part of the last directive.
In the quote above we see that John likely had to fiddle a bit to get the beginnings and endings of the robots.txt file to work. Which isn't surprising. I don't like that this kludging is connected to "good practice" as if it's not an indication of breaking the standards but something "good". Also I disagree with the idea that starting a comment line in robots.txt is "good practice" - good practice is serving a good file. Besides, if starting with a comment helped and he has just argued that things without are ignored - why not just put the word sausages on the first line for the same effect? Hogwash - if there are extra UTF-8 BOMs then putting in a comment is not good practice but just a bad kludge to hide a file structure problem, just like things are necessary here to hide a file structure problem. Let's not argue bad practices are good!
Though the technique is clever. Let's recall the must have requirements for a robots.txt file according to the standard.
The rules MUST be accessible in a file named "/robots.txt" (all lowercase) in the top-level path of the service. The file MUST be UTF-8 encoded (as defined in [RFC3629]) and Internet Media Type "text/plain" (as defined in [RFC2046]).
A WAV file is no longer UTF-8 encoded. What this kludging is doing is saying "this is no longer a valid robots.txt", but is there something we can do to get a particular parser to recognise it as a robots.txt anyway.
It's interesting, but it's hacking in the old sense of the word. Let's not mix this in with "good practice". The effect on other parsers is not known. They could completely ignore the file, interpret it wrongly, or whatever. We are no longer within the realm of standards that tell them what to do. You can check this for yourself. Take https://johnmu.com/robots.txt and put it through some validators. Some work, some don't. The same will be true for robot parsers.
I should just briefly mention that John talks about not hosting the wav file on services that compress the file (they could take the injected robots.txt file out). He injects early on but doesn't mention that parsers can cap how much they parse according to the standard at 500KiB. You definitely don't want to end up placing it after that.
Despite describing it as a nifty feature of the robots.txt standard his article describes a roadblock he reached with serving the file.
Unfortunately, if you just save the audio file as robots.txt and put it on your server, most browsers will show the binary content instead of playing it. To work around that (what fun is it if users can’t immediately play it?), I adjusted the server headers. I ended up using the following server response headers for /robots.txt Content-Type: audio/wav Content-Disposition: inline X-Content-Type-Options; nosniff
It's not really "unfortunate" or "most". All standards compliant browsers will serve content up based on the mime type specified. Here he has changed the type from text/plain to audio/wav to make it actually play as otherwise it's a cool trick but what would be the point? The issue there is that the standard has 3 requirements to be a robots.txt file and being a wav file it automatically broke the UTF-8 encoded one. Changing it from text/plain to audio/wav changes the mime type and breaks a second. Literally we are just left with the fact the filename is robots.txt!
Yes and No. The end effect is awesome and if John Mueller want's to write about it and use it himself then I fully support it. But it also has to be kept in mind that, even though it's his personal blog, his job means people will tend to trust and follow him on this.
The issue is that John starts talking about this as if it is standards compliant, by making up things that it doesn't actually say. He carries on with this idea even at the point he is changing things that guarantee it is no longer a valid, compliant, robots.txt file. There is zero mention of the risks involved so that people can make an objective decision.
He has had to kludge things to get the injected content to be recognised and change the mime type to serve it. There is no way that anybody who understands the technical aspects here would think this was anything that trying to get a non standards compliant file to be recognized by a parser. Yet he goes on to have a section called "test compliance". This is not testing compliance at all. It is testing if a file kludged outside of standards to be seen by Google's parser passes Google's parser. That says a lot more about Google's parsers compliance to the standards and where it allows leeway and what decisions it makes on the "may" sections of the standard, than it says anything about the compliance of the robots.txt file and how it will be interpreted generally and in the future.
What can I say. This was a bad idea, and I’ll do it again.
He knows it is a bad idea. He knows people probably shouldn't copy him. He must know they will. But not only is there no mention of risks, but they're hidden by a whole load of nonsense about "standards" and "compliance". Does it follow the standards? No. Absolutely not. Is it compliant? No.
How something is presented and the circumstances surrounding it is just as important as it being cool. Because people will read it and take everything as true and unknowingly expose themselves to the unmentioned risks.
Start with a free crawl of up to 1,000 URLs and get actionable insights today.
Try The Crawl Tool Free
Why experiment with Googlebot Beyond the fact it is interesting to understand how it works, it is potential useful if you ca...

LLMS.TXT again I've written about LLMS.TXT in the article about how getting one listed in an llms.txt directory mysteriously...

What's this about Adding Other Media to robots.txt I recently came across John Mueller's (a Google Search advocate) blog. I ...

Understanding the Importance of having a fast Mobile website I, personally, spend a lot of time focusing on site speed. The ...
What are robots.txt, sitemap.xml, and llms.txt These files are used by search engines and bots to discover content and to le...

AI Crawlers and Citing Sources The rise of AI, rather than search, crawlers visiting websites and "indexing" information is ...