
April 22, 2025
Some Experiments into How Google's Crawler works
Why experiment with Googlebot Beyond the fact it is interesting to understand how it works, it is potential useful if you ca...
Expert insights, guides, and tips to improve your website's SEO performance

I, personally, spend a lot of time focusing on site speed. The primary driver of that is user experience. Being a marketing industry there's no shortage of studies that reproduce other studies, that reproduce other studies, that come up with statistics for this. Virtually all of the agree that somewhere around 40-50% of customers will abandon a website if it takes more than 3 seconds to load. Most of them argue that visitors connect speed to the quality of the brand.
Generally it's understood that people's attention spans are getting shorter - they're less willing to wait. Because of delays in your brain processing pages a mobile website loading time faster than 100-140ms is going to be perceived as instantaneous by your brain. This is really our ultimate, though highly unachievable, target! In practice I personally use the following boundaries for a whole page being presented to the user:
< 500ms = Fast
< 1000ms = Good
< 2000ms = Okay
> 2000ms = Slow
All of this applies equally to non mobile website pages, but as a lot of visitors are mobile users and as the same factors apply it is useful to think about this more challenging environment. Focusing on mobile performance also has the benefit that it tends to also give quick wins for desktop performance.
Beyond simply user experience. Whilst some may try, it is undeniable that your page speed (being part of user experience) is a ranking factor in search engines like Google. Our own experimentation shows that clearly for direct impact. We also need to take into account that it impacts other ranking signals - because we've already said that user experience is linked to speed and abandoning a website will likely lead the visitor back to Google searching for someone else.
Page speed is an unmissable factor in bringing visitors in and keeping them.
Core Web Vitals refers to various user experience statistics that are considered important for a website. As a web professional, unless you've been hiding under a rock then you will have heard of Page Speed Insights. You may or may not have heard of CrUX. Regular users of The Crawl Tool will have seen this dashboard of user experience/speed data appear in the last few weeks:
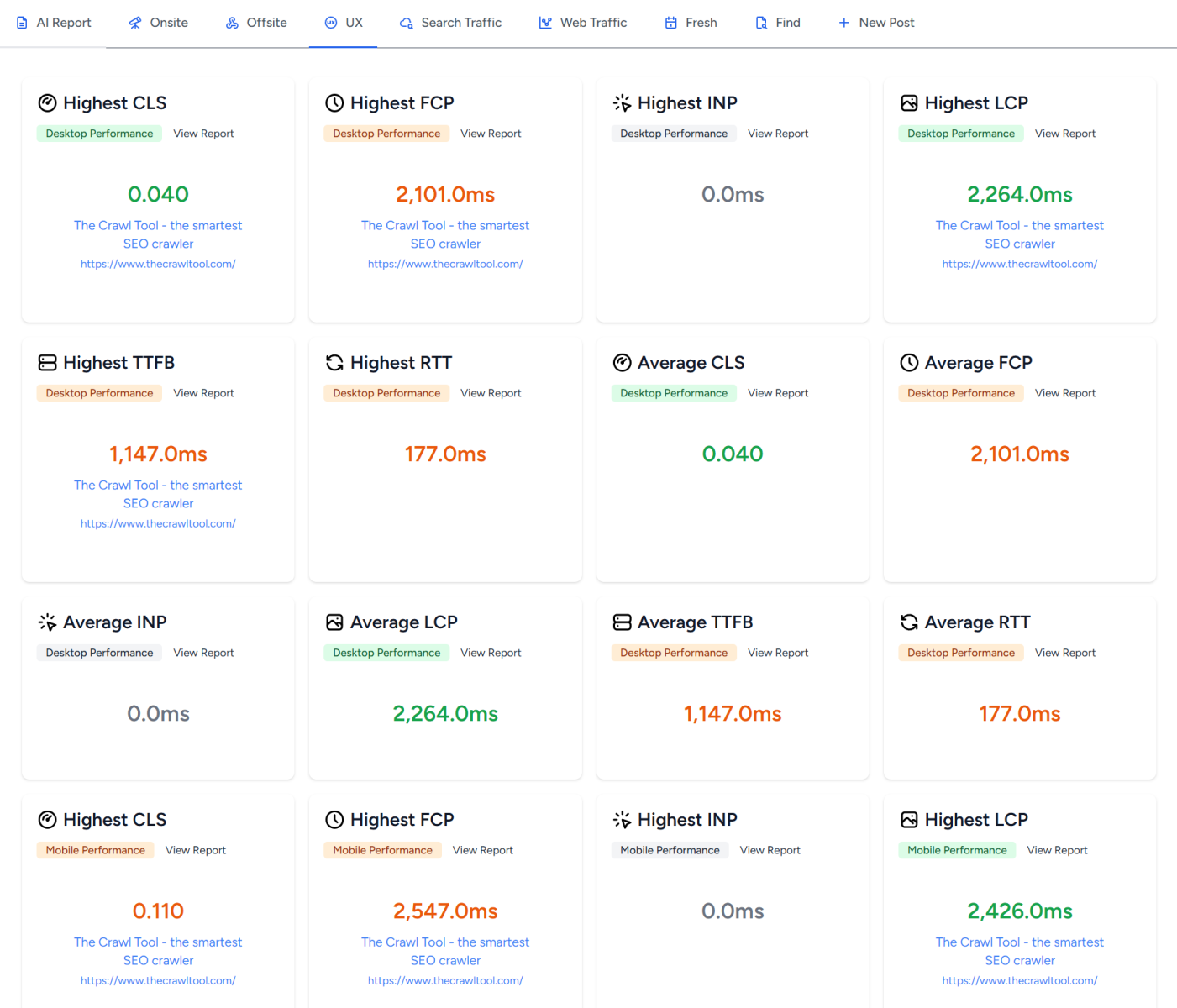
There's also the Lighthouse tool in Chrome Developer Tools. Before we use these tools we should understand them and what they tell us.
Suppose we want to test the speed of a site. We could define our speed factors and measure them. The issue is that if we then ask a friend somewhere else to measure the same thing then we'll get different numbers. There's a vast number of technical factors from which browser is used, to where the user is in relation to the server, to how fast their ISP is, that affects site load speed. And it can affect it significantly.
If I go into Chrome Developer tools and run Lighthouse then I am essentially doing that, I am running it on my machine. That's telling me the experience for me, but not necessarily the experience for others in terms of speed. Various caches on the internet that are outside of our control also change things. Run it for the first time on a site and you'll get one set of figures but run it a second time and you'll get a faster set. It gets worse! We're most interested in the mobile experience because that's the slowest/hardest case for us but we're running it on a desktop. We can tell Lighthouse to do a mobile report but the fact it is mobile is simulated. Or in other words it's artificial. It gets worse - running Lighthouse locally means it can be affected by whatever else your computer is doing, or extensions in the chrome browser, which may change from run to run. You can mitigate this a little bit by running it in a private browser window to stop extensions. But worse still with Lighthouse Google have done the thing that is oh so common with other SEO tools too - they've abstracted data into scores out of 100 a lot. So you don't get to see the full detail necessary and people happily report scores over "90" but have no clue what that means. Yet Lighthouse in Chrome Developer tools is my most used tool when actually working on website performance - why? Because it's fast and because whilst we should take the figures with a certain amount of skepticism, this doesn't apply so much if you view figures as relative. If you change something and reduce a time to a quarter of what it was before then you have still likely improved the time to a quarter of what it was before and it's a positive change. Less so with the scores out of 100, but still if you make a significant improvement and that improvement is stable then it suggests a positive change.
On Google's page speed insights you can analyze a url and you will get a section titled "Discover what your real users are experiencing" which we will ignore for now and come back to later. After a while under that you will get a section "Diagnose performance issues" which tells you the same details as if you ran Lighthouse in developer tools in Chrome. Because it's just Lighthouse run from Google's servers. It has all the same problems - try running the same URL twice and you'll often get different scores. Quite often the second run is dramatically improved.
So let's circle to CrUX. The Crawl Tool's own data is built on CrUX. It's also where the data comes from for the top section in Google's Page Speed Insights. Google tells us this about CrUX data:
CrUX data is collected from real browsers around the world, based on certain browser options which determine user eligibility. A set of dimensions and metrics are collected which allow site owners to determine how users experience their sites
Or, in other words, based on unspecified options chrome spies on users and sends this data back to the CrUX report. This is interesting data because unlike asking a friend to check for you - this is like asking lots of people to check for you and is likely to be much more geographically dispersed (and dispersed over your region if your site has regional focus).
Google has an API for accessing CrUX data - which is what the crawl tool is. The API only gives data if an unspecified minimum number of people have visited a page, but that makes sense as with low numbers you aren't really gaining accuracy over running Lighthouse yourself. And it averages over 28 days. In other words it takes time and volume to get a more accurate estimate. This means we can't use it for assessing short term changes (use Lighthouse) but we can for checking in the long run how people are experiencing the web pages.
The top section on the Google Page Speed Insights tool is the same. But with one critical difference that you can see if you fill in a url with a very low volume of traffic. You'll get a result. The section will look the same and have statistics. The legend will still tell you there are many samples over a 28 day collection period:

There's an indicator on the top left that it has fallen back to origin. But my point is it is not clear to practically everyone that it is showing aggregate and not page data. Which is really important to know. As a side not - a good thing about Page Speed Insights is you can run it on any site, try running it against search results and you'll mostly see that those sites ranking that don't have massive backlinks have very good scores.
In short - in terms of measurement there's no perfect way. But use Lighthouse in Chrome Developer tools in a private browser instance for tests of changes you are making in the short term and use The Crawl Tool's reports for long term monitoring due to that greater clarity where there isn't enough data.
There's no shortage of articles that will tell you what all the technical indicators are. So here I want to take a different approach and walk through the journey of what happens when a visitor's mobile browser requests a web page. Or at least the things that are or could be under your control.
The browser is going to ask the devices operating system to convert the web address into an IP (number). This asks a server on the internet for this data. That server may have it cached, it may not, and it may ask another server. A DNS request can take between 20ms and 120ms depending on how fast the servers are and how much caching there is. Let's think back to the introduction to this article. If instantaneous means 100 - 140ms, then a slow response here is nearly all of that bracket. That's why I said instantaneous is all but impossible. But of our fast speed of 500ms, it could still be 1/5th of it. We also start to see the first reason why different runs of tools other than CrUX based ones shows different speeds. There could be a 20 to 120ms difference just due to caching.
There are actually two things that you control that can impact this. The first is the TTL and the second is who is hosting the DNS.
Let's cover TTL first. For most records you can set a TTL. We're interested in doing so here for "A records" that convert the domain or subdomains to ip address numbers. What a TTL does is tells other DNS servers it should cache the result for a number of seconds. They don't always follow it, but what we're mostly interested in having happen here is have your visitors ISPs cache the result. Why? Because in that case the visitors device asks their ISP for to look it up, it's in cache so it can return it in the fastest possible way without having to ask other servers. So if you can keep the DNS request cached for longer you reduce this time period. Now there are a lot of ISPs in the world so it's impact isn't going to be consistent. Also a lot of them cache longer than the TTL anyway. But there are a lot less mobile service providers and the impact is not insignificant. The maximum you can set this too is 2147483647 seconds - or 68 years. So we should probably talk about the drawbacks of setting it too long. In the future, if you change the ip address that the domain points to then you have to wait this long to be sure that every DNS server that could possibly have cached it has stopped caching it and won't send visitors to the old ip address. 68 years might be a long time to wait.
Now let's talk the actual DNS host speed. When you host your website then normally you get your DNS hosting from the same provider. If not then you might get your DNS hosting from the people you bought the domain from. I like this tool for visualizing how fast DNS response is from around the world. Find a site that is using the provider you have (possibly the site you are working on) and use it to evaluate if the response is good where your customers are located.
Not just because they gave us free credits - but I kind of like the DNS speed when you proxy a site through Cloudflare. It's almost always fast with very little geographic variation. There's a few slow spots as you'd expect but it's one of the best you'll see. Interestingly Cloudflare sets the TTL to 5 minutes - I've not changed that because I think there's some agreements with ISPs or ISPs have unilaterally decided to keep Cloudflare data longer as it acts like longer when I've made changes in the past. But I digress, find a fast DNS provider and set your TTL as long as you can tolerate.
Great. The mobile device has got the IP address. Ever since Google decided that it was a good idea to force everybody to have SSL certificates by throwing up a warning message in Chrome and not listing sites without it, even sites that are just informational and don't have any reason to need SSL whatsoever must suffer the speed impact of negotiating an SSL certificate whether it is necessary or not as it's a virtual requirement. Put simply there will be a number of messages sent backwards and forwards to check the server is who it says it is and to establish the parameters for encrypting traffic. In The Crawl Tool's UX tab or the UX Speed Phone report you can see the RTT. RTT (Round Trip Time) is the time it takes for a request to go from the browser to the server and back again. Whilst we can't control the actual SSL itself, this gives us two things we can do to save time in the SSL negotiation by adjusting the number and speed of round trips.
The latest version of this negotiation (TLS1.3) requires one round trip. The previous version TLS1.2 required two. So make sure wherever you are hosting the site can support TLS1.3. It's literally an easy win in terms of time.
The second thing we can do here is to move the TLS negotiation closer to the visitor as that's going to reduce the RTT! At the risk of sounding like a Cloudflare advert - there's an easy way to get the negotiation closer to the visitor if your server is looking to serve internationally. If you serve just a small geographic region then a fast server in that area is probably fine.
Now there is one further thing we can do. It's called 0-RTT. Which stands for 0 Round Trip Time. Yes please! This slightly reduces security so ecommerce sites probably wouldn't want to do this, but if your site is purely informational and has been forced into SSL by Google's measures mentioned earlier then this is something you want. Not a lot of hosts support it though. (In Cloudflare it is not turned on by default, but you can turn it on).
Now the visitor's browser is going to ask for the web page. It's generally going to do so using the fastest possible HTTP protocol. HTTP stands for Hyper Text Transfer Protocol. Which is going to really annoy the kind of people who read this article and are interested in the little details because everyone, including the standard staters, are basically saying Hyper Text Transfer Protocol Protocol every time they say it!
In the early days of the internet HTTP started off very simple. For each resource a browser wanted it made a connection to a server and asked for it. The assumption was there was one website on a single server. So this was pretty easy. Every resource like an image also needed a connection to download it. When the resource was received, the connection was closed. There's overhead in those multiple connections but it probably didn't matter much when images were more of a rarity and css and javascript weren't born. This was HTTP/1.0 - nobody uses this anymore and if they do they should be locked up.
However, people started to address this inefficiency by not closing the connections. That allowed browers to request HTML, receive it, not close the connection but instead ask for another resource - like an image. This was eventually incorporated officially into HTTP/1.1. Also in HTTP/1.1 was the ability to have multiple websites on a server. This may seem pretty basic but it worked for a long time and a everybody was happy with it, some people still are.
But here's the problem - HTTP/1.1 isn't very efficient for encrypted (SSL) transfers because you must negotiate the SSL for each connection. One can imagine that the idea behind not closing the connection in HTTP/1.1 is that a browser can make a single connection, request the HTML, and request every resource on it afterwards, sequentially. So there'd only be one negotiation. But that's not the way browsers worked (and work) in practice with this - they make multiple connections (up to 8) so they can download things in parallel. That speeds things up but gives you multiple negotiations.
The solution is to either waste server resources (set up many parallel connections all at once and negotiate the SSL in parallel) or design a better protocol that can handle everything in parallel in a single encrypted connection. We could call that HTTP/2, and that's basically what they did. Another major, related, improvement in the protocol is the ability for the server to push stuff that the server expects the browser will need. That can cut the overhead of requesting it, but I don't think it is used hardly at all. There's a lot of misunderstand about HTTP/2 and when it is better. It is essentially about serving multiple resources over a single encrypted connection. If the site is very very simple then the complexity is probably not worth it and may actually be slower (because of the overhead) but in most practically scenarios and because of the enforced use of SSL even on sites that don't need it - in practical terms it is going to be faster for nearly all websites. It's also commonly supported. So going back to our speed thing - make sure your website host has the ability to serve HTTP/2. Oddly, by default, when installing some web servers it only has HTTP/1.1.
Then we have to talk about HTTP/3. HTTP/3 is basically what happens when internet protocol designers get drunk and take things too far. The previous HTTP versions work over a protocol called TCP. This breaks all the data down into chunks named as packets, confirms their delivery, and reassembles them at the other end. The problem is if a packet doesn't get to the destination then it is requested but all other packets after it must wait until it is delivered. With the HTTP2 protocol this effectively stalls everything until the packets can be reassembled. This can occur, but in practice not so much that we need an entire new protocol for it. HTTP3 uses a different protocol over UDP, which is all we need to understand. The primary issue here is that most of the internet is set up to allow TCP connections for web and not allow UDP connections. Until that changes, which there's little sign of happening, then it's simply more complexity for little benefit. If your host serves HTTP/3 then you should be happy. But I wouldn't consider it an essential.
Great. So the request is made and we need to serve the web page. Most modern websites are backed by some sort of database. Let's be clear here - even the fastest databases are actually sluggishly slow in terms of the kind of timings we're talking about here. If we can avoid making database calls then we should. That gives us two kinds of caching - we can cache the page that the visitor will see and we can cache the database calls themselves. Let's concentrate first on caching the page.
Assume our home page rarely changes. Every time it changes we could make a copy of it and just give that to visitors. Then for nearly every visit (except the first one after it changed) we save ourselves time by not making that database call. Our server can respond quicker and so the visitor gets the page quicker. Win!
Now to be clear here - for many modern websites this is easier said then done. Informational sites don't change much, but for more dynamic sites like e-commerce the basket might change per user. This comes down to better design/architecture - it's up to a developer to create a structure where the page remains the same but elements can change after serving to reflect this.
Where that can't be done then a site should cache database calls. Actually, they should cache them anyway.
The idea here is that we serve the page as quickly as possible by minimizing things that are time expensive for the server to do.
The cached page is what we give the visitor. There's a few things this means for us. The most obvious is that we can send headers to tell their browser to cache it seen as it doesn't change. It's not going to show up in any of the statistics we mentioned earlier, but the fastest page server is a page the browser doesn't have to fetch at all! But the other is that there is now a level of independence between the cached page and the server that means we don't necessarily need to serve it from the server but can serve it from a location closer to the end user. This is known as edge caching. The visitor benefits by not having to wait for the RTT to your web server but just the quicker RTT to a stored cache near them. (Again, sites like Cloudflare do this).
I can only touch on this bit really briefly or this post will be really long. But this is a topic most web developers don't understand well when creating dynamic sites and one where dynamic sites can most benefit from user experience (and therefore improve the site effectiveness/revenues).
For many reading this article you'll have a site on Wordpress. Then my advice to you is Cloudflare will take care of the earlier DNS and SSL improvements for you. By default it caches images and things that rarely change and you can have this all for free! It doesn't cache the actual pages by default though. You could set it up but it is rather tricky and restrictions mean it isn't practical in some cases. They have an extension for Cloudflare APO, which at the time of writing is $5 per month. Oddly it doesn't have the best reviews, I suspect because of a lack of understanding about it, but between you and me that's a bargain.
but I wanted to be clear where we are here in the process. The browser has got the HTML of your web page! Hopefully the things above give an understanding of how to get your pages to users quicker. But I also wanted to give people a massive hint in terms of crawl budget (how often Google is willing to crawl your site). If you have Google Search Console go to Settings and then Crawl Stats, you'll see something like this:
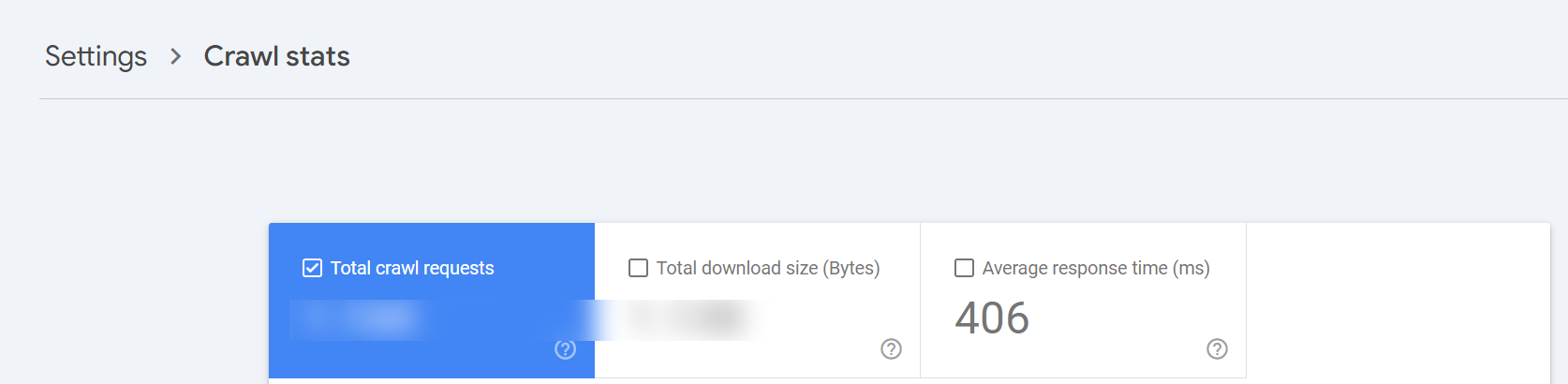
Average response time here is the time from starting the request to having obtained the HTML (the point where our description is up to). It isn't in the crawl stats for no reason ;)
In an ideal world our server is going to start serving the browser resources before it even requests them. In practice that rarely happens and the browsers make the requests.
The first bit I will say here isn't really relevant to you if you just run a site in a CMS, but it is relevant if you're a developer. In the days of HTTP/1.1 we would bundle up resources to make then into as few files as possible. This made things faster by reducing the overhead of making multiple requests. There is a temptation to look at HTTP/2.0 and realize that the concept of files doesn't apply there anymore really as they are sent over the same connection. One file or 100 files isn't really any different in terms of the HTTP/2.0 protocol. The issue comes when you don't look further than that and think that means it doesn't matter if you server one or 100 files, it doesn't matter if you bundle things or not. You need to look further just outside both ends of the chain to find out where the true overheads are - think about the storage. Is there more overhead in finding, retrieving, and serving one file or 100? Is there more overhead in a browser caching and processing one file or 100? Granted we're talking about very small amounts of time here, but we're also talking about small amounts of time making a big difference in general. There's no difference in how you should approach bundling and caching just because the protocol changed.
Okay, back to everyone. Our resources will generally consist of images, css, and javascript. Potentially other things but let's consider these the key things. Because these things don't change much they should be in cache and browser cache. But images require more focus, particularly when we're talking about mobile.
In modern times it is common for resources like javascript libraries or fonts to come from multiple sites. That has some advantages in terms of managing them and security, but also some security disadvantages and more some performance disadvantages. Whilst the CDNs they are on are generally fast - you should remember that your site is only going to be as fast as the slowest.
Which is my way of saying that for speed purposes you want them all on the same site (preferably bundled with other stuff if possible) and served from the same edge cache. (btw on cloudflare you should use google fonts and turn on the option in cloudflare to convert that to their own).
There are lots of fancy things you can do with prefetching DNS connections for where resources are located. These are kludges. If a site is doing then it is something to look at improving. Not only is centralizing resources a good thing for performance, but it also reduces points of failure.
If you're on Cloudflare turn on Polish and Mirage and happy days. These options compress your images and try to adjust them to mobile devices. For anyone else it's going to get a little more complicated.
Let's start with the easiest thing - images on mobile. It may well be the case that you don't want some images to display on mobile. Here's the good news - if you set display:none on an image then the browser won't bother requesting it. That means you can use media queries to very quickly eliminate those images and speed up pages.
You should also make sure you have lazy loading by adding loading="lazy" to all images except those that would be obviously above the fold when viewed.
Again the influence of Google (this time Google discover) probably means you'll want a large image (with dimensions that are minimum 1200px), but consider using srcset to serve different images in different circumstances. Don't expect your user's mobile device to download huge images.
Google recommends you use webp for the image format when browsers support it. It's been around long enough now that every major browser does. So you could do that. That is probably an easy solution. Webp is heavily sold as being small, but I'm not convinced that it is smaller than png files when compressed with something like oxipng. The latter is going to be a lot of work though, so you'd probably want to do some sort of cost/benefit analysis.
Note on this - Google indexes on a mobile first basis. That means it probably makes sense to do these optimizations even if you only really serve to desktop users. I know, it sounds bonkers, but welcome to the modern world!
The browser is going to render the page. It's actually started after it got the HTML but we'll consider it mostly as being at this point in our process. You'll probably have read about LCP (Largest Contentful Paint). This is trying to assess how quickly the main content of the site is visible to users. This is important as we want our website to be rendered quickly for them, but it's also the one thing that's hardest to do anything about and where the tools give the least reliable information (in my opinion).
In tools like Lighthouse Google will tell you to set widths and heights on your images. That's easier said than done when our websites also need to be responsive to work on about 10 billion different devices. Things like srcset mentioned earlier help with this but only a bit and it doesn't feel like a solution. So yes - our images would render quicker if we put widths and heights. Even quicker if they didn't need scaling. (mentioning Cloudflare again - this is what polish tries to help with. if you have it - turn it on).
In practice I find it better to have large content above the fold be text rather than images where possible as this renders faster. That may (quite likely will) go against your design goals. But it's interesting to observe that these days more and more sites are simplifying to less image based above the fold content and this is the reason why. Having said that somebody is, of course, going to point out lots of big brands that don't. The thing is there they've taken the decision that they benefit more from the images than the time cost loses them sales. It's something that brand recognition, having a lot of link authority, and the fact that somebody is probably there to engage with that brand and therefore a bit less impacted by time, can help with. You need to decide if you're in that position.
The process here is for mobile sites, but a lot of it applies to desktop too. Because search engines like Google index mobile first, it's sensible to have our work processes also start with mobile first. Do these and then switch to desktop and you'll get a nice surprise.
In my experience nearly all sites can improve speed substantially and see improvements. Fast sites get crawled more, they rank higher, the please their visitors, and the increase sales. I'm not saying you necessarily have to do every one of these things on your site. But you should consider them given the benefits they bring. In the days of dial up we'd happily wait 30 seconds to a minute for a page to download. Today, you've lost them in a second or two!
Start with a free crawl of up to 1,000 URLs and get actionable insights today.
Try The Crawl Tool Free
Why experiment with Googlebot Beyond the fact it is interesting to understand how it works, it is potential useful if you ca...

LLMS.TXT again I've written about LLMS.TXT in the article about how getting one listed in an llms.txt directory mysteriously...

What's this about Adding Other Media to robots.txt I recently came across John Mueller's (a Google Search advocate) blog. I ...

Understanding the Importance of having a fast Mobile website I, personally, spend a lot of time focusing on site speed. The ...
What are robots.txt, sitemap.xml, and llms.txt These files are used by search engines and bots to discover content and to le...

AI Crawlers and Citing Sources The rise of AI, rather than search, crawlers visiting websites and "indexing" information is ...