
April 22, 2025
Some Experiments into How Google's Crawler works
Why experiment with Googlebot Beyond the fact it is interesting to understand how it works, it is potential useful if you ca...
Expert insights, guides, and tips to improve your website's SEO performance

I've written about LLMS.TXT in the article about how getting one listed in an llms.txt directory mysteriously made a crawler show up. It's mentioned as one of the things tracked in our cloudflare tool to track robots.txt, sitemap.xml and llms.txt calls. And I've previously mentioned it on twitter when thinking about incorporating LLMS.txt functionality into the crawl tool.
Let's recall - llms.txt is a proposal, not a standard, that web site owners can make it easier for crawlers (or indeed any programmatic reader of content) by putting information in markdown format in a file called llms.txt in the root of your site. Typically that will refer to a list of urls of pages or markdown and text information about them. But it could include more. There's an equivalent file called llms-full.txt where you could put more details if you wanted to.
Primarily I'd imagine AI agents can use this to gather information to direct their subsequent actions (e.g. which pages they should read) or directly return information. I've speculated before that the easiest way to use llms.txt is to just copy and paste it into an text AI and then just ask it questions. As Large Language Models are coming with increasingly larger and larger context windows this makes more and more sense. Theoretically you could feed most websites and html into them, but that comes with an associated increased cost due to the extra token usage from the extraneous information.
People have recently been talking about llms.txt in the SEO world in the context of just how useful is it in comparison with the time taken to make one. To make this long story short - it appears to currently be the turn of the "llms.txt is pointless" SEO crowd to push their narrative.
I want to encourage people to think more logically and as we'll see if we don't just take these arguments at face value then none of them have any basis.
A lot of the recent case against comes from this reddit thread. It has given rise to twitter discussions and an article on Search Engine Journal. There are 3 main points, so let's delve in:
This argument often comes first. The idea of llms.txt came from a third party and it is indeed true that none of the AI providers have said they use them. I'm going to pick on Google's John Mueller's comment in the reddit thread for this one, because, well, he's a Google employee so his comment is likely to be more influential on an SEO subreddit.
AFAIK none of the AI services have said they're using LLMs.TXT (and you can tell when you look at your server logs that they don't even check for it). To me, it's comparable to the keywords meta tag - this is what a site-owner claims their site is about ... (Is the site really like that? well, you can check it. At that point, why not just check the site directly?)
He makes this claim "none of the AI services have said they're using LLMs.TXT".
But what does "using" mean here. For LLMs.TXT we can actually think of three things that would qualify as using it:
Anthropic's documentation site has an llm file. So we can say that for the first type of "use" they use it and presumably must've had some reasoning for putting it up in the first place (I would guess for AI agents, but let's not put words in their mouths!).
If I go to ChatGPT I can push it with questions and it will download /llms-full.txt:
"GET /llms-full.txt HTTP/2.0" 200 62176 "-" "Mozilla/5.0 AppleWebKit/537.36 (KHTML, like Gecko); compatible; ChatGPT-User/1.0; +https://openai.com/bot"
At least in an agentic sense it must be consuming it. An interesting side note on this is that it appears to know what pages/files are on my site and that aligns more with Google than Bing (I thought OpenAI were connected to Microsoft? perhaps I'm losing track! Also of note for later - I tried a site without llms.txt or llms-full.txt and couldn't get it to try to fetch it and 404). It is probably programmed behaviour, but it is perfectly possible it learned to ask for this file. If it learned it, would the AI Providers necessarily know to say so?
In both the first two senses of using - they categorically do. So to give Mueller the benefit of the doubt we have to assume that Mueller is only talking about the using it for the crawling and training of LLMs.
The text I've quoted is a very common Google way of saying things. It says "none of the AI services have said they're using LLMs.TXT" and leaves us to fill in the obvious bit that is left out but they imply: "so they aren't". Then it's us that have made the non sequitur and completely deniable that they said it. Even though everybody reading it will read that.
It of course, doesn't follow that they aren't using it just because they haven't said so. We've already established that if an AI learns to use tools then they might not even know. Not saying so says absolutely nothing about what somebody is or isn't doing. Look at the things around you right now - how many have you told people you are using and how many not? There has to be a reason to say you're using something, otherwise isn't the default that you just don't say?
It's odd, because the reverse argument (that contains all the same fallacies) of "They haven't said so so they are using it" would cause uproar!
We've had to be very specific to get past the fact that for providing one to be consumed and for agentic use there are examples that would prove it wrong. But even if we're that kind then the problem for anybody pushing this argument is that it relies on a logical fallacy. Nobody saying they use it actually says nothing about whether somebody is using it or not. There's words, but they're meaningless - there's no argument here.
An argument that shows up in the reddit thread, is a lack of fetching llms.txt. There's a point here about somebody who claims to host over 20,000 domains that hasn't seen it fetched other than by "niche bots". That's repeated in the Search Engine Journal article. I've thought hard about this and whilst 20,000 domains sounds impressive and a lot, we actually have too little information here. 20,000 domains of how many pages? How much information does that represent? Do all 20,000 actually have an llms.txt (as at least one agent seems to not fetch llms-full.txt unless they know it exists). So beyond that mention I'm going to keep things shorter by discounting it. Which does make it seem like I've been picking on the google rep lately! But he says...
and you can tell when you look at your server logs that they don't even check for it
This kind of argument I've seen at least twice this week alone and I wish I knew the name for it. Someone making this kid of argument points to a source of information, tells you what it will say, but relies on the fact that you won't check. In this case people have had someone say 20,000 domains didn't have a single case. The words are from a google rep that commands some respect on the topic. Most people wouldn't know how to check it even if there wasn't a huge amount of social pressure and he's told you what you'll find "they don't even check for it" so why bother?
We already know that agent use can fetch llms-full.txt. So if you have the files and check the logs then we can assume that there is a non zero chance that what Meuller says here is actually true and you could find something.
Since I set up tracking for llms.txt, sitemap.xml and robots.txt my llms.txt has been request 27 times in a 7 day period. That is not a lot, but it is not zero. So I think we can decide that the idea it isn't crawled at all is hogwash.
I should say a couple of things about this. The first thing I can say is that the sitemap.xml has been crawled more, and the robots.txt over double the amount. This is not a robots.txt file which crawlers should recheck if it's older than 24 hours when they want to crawl. It's doesn't need that much traffic and if you're looking for that you'll miss it. It's closer to a sitemap.xml.
Secondly some of these requests obviously come from AI providers. Like the one in the second line here reading...um....what file could that possibly be!
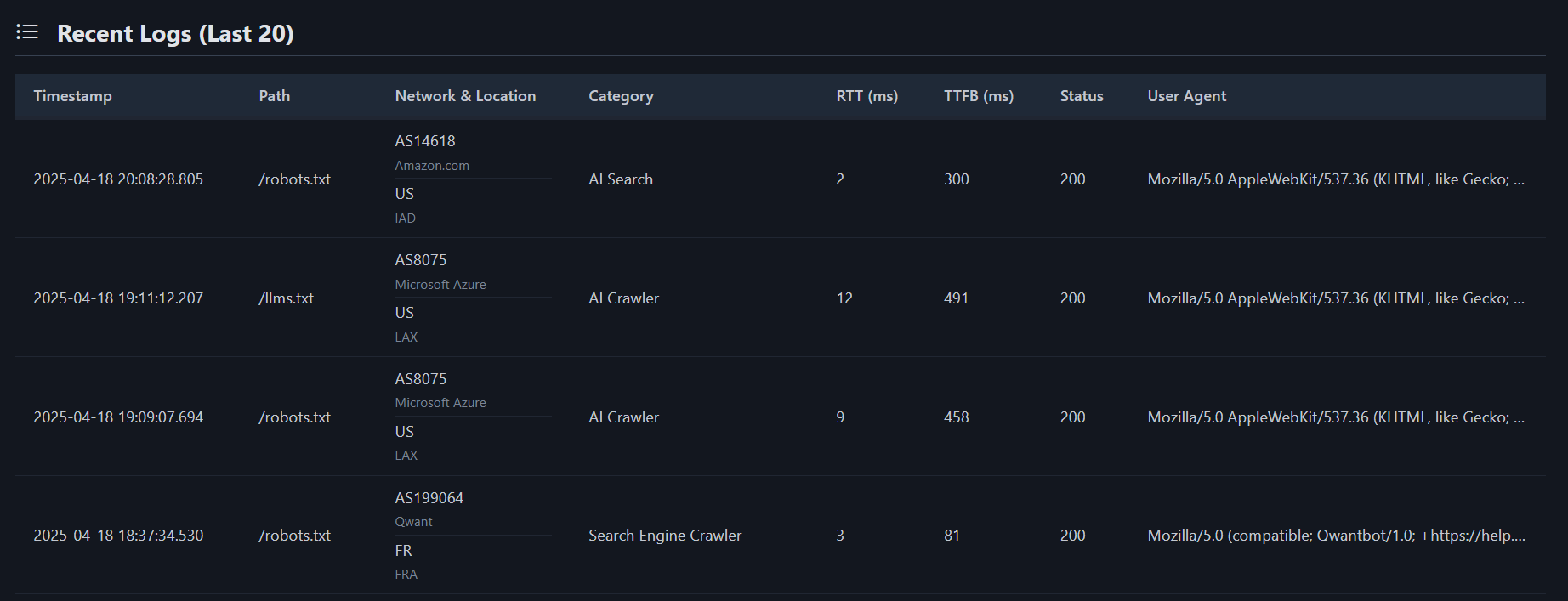
And the apache log for the same and the llms-full.txt that it also fetched:
[18/Apr/2025:19:09:07 +0000] "GET /robots.txt HTTP/2.0" 200 251 "-" "Mozilla/5.0 AppleWebKit/537.36 (KHTML, like Gecko; compatible; GPTBot/1.2; +https://openai.com/gptbot)"
[18/Apr/2025:19:11:12 +0000] "GET /llms.txt HTTP/2.0" 200 4757 "-" "Mozilla/5.0 AppleWebKit/537.36 (KHTML, like Gecko; compatible; GPTBot/1.2; +https://openai.com/gptbot)"
[18/Apr/2025:19:12:27 +0000] "GET /llms-full.txt HTTP/2.0" 200 62176 "-" "Mozilla/5.0 AppleWebKit/537.36 (KHTML, like Gecko; compatible; GPTBot/1.2; +https://openai.com/gptbot)"
Others come from data centers and are bots. Bots are meant to set their user agent to identify themselves, often they don't. Some of these are bad bots, some of these are likely AI in disguise. It's hard to separate the two out and you can never 100% prove those. However, consider that the average reading rate of llms.txt is 6.5 hours.
When I was testing a few other AI options this happened literally a minute after it couldn't give an answer to a question.

Would I say these last two were definitely AI bots? No. Would I say the circumstances indicate it is likely they are and in disguise - yes.
But let's wrap this section. I don't think we need to say too much about this. They fetch llms.txt and it shows in the server logs.
And the AI is going to crawl the page anyway - it's redundant. Let's pull the bit from the google rep's quote:
To me, it's comparable to the keywords meta tag - this is what a site-owner claims their site is about ... (Is the site really like that? well, you can check it. At that point, why not just check the site directly?)
With the llms.txt we have the file and then possibly markup pages for pages. But essentially the real pages are separate entities. The base llms.txt can be thought of as a summary of the site which contains summaries of pages.
Keywords meta tags don't work the same way. Mueller's analogy breaks as soon as you realize that the keywords meta tag is not what a site-owner claims their site is about - it's what they claim a page is about, and on that very same page. That is a very important distinction because for keywords meta tags the crawler has already expended resources to fetch the page.
Then the answer to Mueller's question becomes obvious:
It's probably worth noting here that there are different end goals. In the old days of search engines if you set up a keywords meta tag of "cheese" on your page about "frogs", then without the search engine pre-checking your page about "frogs" could be served when somebody searched for "cheese". That would be a surprise for the searcher and would be why Mueller feels the need to check.
An LLM is not a search engine though. If the llms.txt says the page is about "cheese" and it's actually about "frogs" then when the large language model is being trained it is learning about frogs, not cheese.
Only when looking for information as an agent could it potentially be a problem but then the agent has already had signals that made it come to the site looking for the information (i.e. it almost certainly knows it is about frogs and not cheese).
I think in this case it's more a lack of understanding that it's far harder to spam an AI than it is to spam a search engine. But the two initial problems with this argument is that it tries to compare something applicable site wide with something that occurs on the same page it's describing and that it misunderstands the effect on the process of what would be "spam".
Still, there's an aspect of the argument that is about duplication. Coming from a developer background it's inherently built into me to dislike duplication - if you're duplicating a bit of code then that's when you know you should create a re-usable function. Somebody needs to tell AI coding tools!
But presenting the same content in different ways in ways that are more convenient for different readers (human and machine) to read isn't duplication and it's not a new concept. Google spent ages trying to convince us to make Amp pages. That's maybe not the best example because hands up anybody who still bothers? But if you're presenting the meta descriptions or twitter card description or open graph description in a page and in llms.txt or your presenting the html content of the page in a markdown file - is that duplication or is it simply doing the same thing they were asking us to do with Amp and providing the same things in ways that certain visitors can process more easily?
Let's speculate we run an AI crawler. When I say speculate I mean we don't know anybody does this and we wouldn't expect them to say (Google don't give the same information on their crawler), but logically it makes sense. Our crawler has a lot of knowledge. We know exactly what we trained it on because we were clever and created embeddings for the training material. For any bit of information we process we could create an embedding for it and see how much knowledge it might add to our LLM (roughly) by seeing how much similar information we've fed in. So we crawl every page on the site, create vector embeddings, and compare them. If we have have a really large amount of information about something then it's probably not worth the GPU time for training. So we'll just toss those pages. Shame we downloaded them but there's more information than we can possibly train with our GPUs at the moment. But wait - isn't it better if we created a vector embedding from llms.txt and compare that to tell us what information the site has in comparison to we have? For these sites we can know how likely it is they have information we want to train on. We can then prioritise our crawling to sites that most likely have information we need. Now if somebody lies in llms.txt and says it is "cheese" and it turns out to be about "frogs" it's affected that prioritization slightly but we can still train about frogs and it'll show up when we compare the vector embeddings so we can just stop crawling that site. Haven't we got super efficient in directing our crawler precisely by not doing what the google rep suggests?!
The argument Meuller, and anybody else making the same one, tries to make here is wrong because it tries to draw comparisons about things that are not the same. Simply put - they're comparing apples to oranges and telling you what should happen based on the assumption that an apple is an orange. An apple is, however, not an orange.
So we need to make a conclusion. I've not really hidden that my intent has mostly been to use it to point out a problem in the SEO field - a lack of logic that allows people to be misled by vague statements and claims that there are myths and mythbusters.
But having shown these arguments for what they are, complete and utter nonsense. Perhaps we should also draw a conclusion on LLMs.txt as that is what it is primarily about, yes it does get used, and crawled, in some cases. Should you do it?
That depends. There's an argument that your pages being used as training data is unfair and undesirable. It's this unfairness that means people are more likely to buy into the nonsense and blatantly false arguments we've talked about. But there's another side - it can be used by agents or people just passing it into an LLM to ask questions. To engage with the material on your site. If you're not doing that yourself, or not doing it well, then others will and that could be a potential net positive for you. LLMs.txt enables that and there is a cost difference between processing an LLMs.txt file and html files that is in some way always going to end up with the end user. Whilst we can yes/no the silly arguments given by others, answering the question of should you do it is something only you can do for your sites.
Whilst we know that it isn't the nothing that some people would like to baselessly claim. We don't know how much impact it will have or how much it will help your site.
There's an increasing tendency for people pushing claims without logical backing to simply claim they are helping you save time and get their quicker. It's something the google rep from most of the arguments does a lot, but it's repeated by others. The issue is that not the google rep himself (that has only commented on length and ranking) but others have pushed meta descriptions as a myth. You should always have a short description of your page - not just for meta descriptions, but for your twitter cards and your open graph, and for...this. If you've followed those people then you're in a tough spot. Ironically you'll get there slower. But it is worth you creating them. Not just for llms.txt but for all those other reasons. The marginal cost of then doing llms.txt is tiny. But it's understandable if this is the situation you're in then unclear benefits may increase your reluctance to do it.
If you have them then there are services to do this, it's really just representing data a different way, there are wordpress plugins, and a developer can pull it out of your database in 5 minutes.
It's your choice. Just don't be influenced by people claiming nonsense.
Start with a free crawl of up to 1,000 URLs and get actionable insights today.
Try The Crawl Tool Free
Why experiment with Googlebot Beyond the fact it is interesting to understand how it works, it is potential useful if you ca...

LLMS.TXT again I've written about LLMS.TXT in the article about how getting one listed in an llms.txt directory mysteriously...

What's this about Adding Other Media to robots.txt I recently came across John Mueller's (a Google Search advocate) blog. I ...

Understanding the Importance of having a fast Mobile website I, personally, spend a lot of time focusing on site speed. The ...
What are robots.txt, sitemap.xml, and llms.txt These files are used by search engines and bots to discover content and to le...

AI Crawlers and Citing Sources The rise of AI, rather than search, crawlers visiting websites and "indexing" information is ...