
April 22, 2025
Some Experiments into How Google's Crawler works
Why experiment with Googlebot Beyond the fact it is interesting to understand how it works, it is potential useful if you ca...
Expert insights, guides, and tips to improve your website's SEO performance

The file robots.txt in the root of your website allows you to specify which search engines can crawl what. This is useful to focus crawler attention on content pages, reduce duplicate content, and to reduce the load on your website.
The robots.txt standard is a very old standard and what many do not know is that quite a lot of it is subject to interpretation. The problem with most tools that allow you to check your robots.txt file and functionality that don't come from the search engines themselves is that it is difficult to be accurate when, at best, you're just working off a description to implement them.
We've added robots.txt functionality to The Crawl Tool, but to overcome these problems we've done it a little differently.
In this github repository, Google provides code from their Googlebot crawler in the form of a library that can integrate with other software. Theoretically you can integrate this code with your software and get a reliable interpretation of robots.txt files using their assumptions on how to interpret it.
Perfect! Except this is C++ code. This means it can easily be integrated into C or C++ software, but none of the main SEO tools are using that. Certainly in the cloud based tools space, which The Crawl Tool occupies, this isn't useable as it stands.
Really the code is made primarily for writing a program in C/C++ that then uses this library.
WASM is a technology that enables web browsers to run more traditional code. Such as C++ code! In principal there is a way to run it then.
Firstly somebody would have to write a program that provides functionality to call Google's code. Then secondly, they must package it all up as a WASM file to make it usable in the browser.
That's easier said than done, but with much trial and error - that's exactly what we've done at The Crawl Tool.
This provides The Crawl Tool with a very unique functionality. Not only is it the only web based SEO tool that can be confident of their robots.txt implementation's accuracy but also we can check large numbers of web page links in parallel.
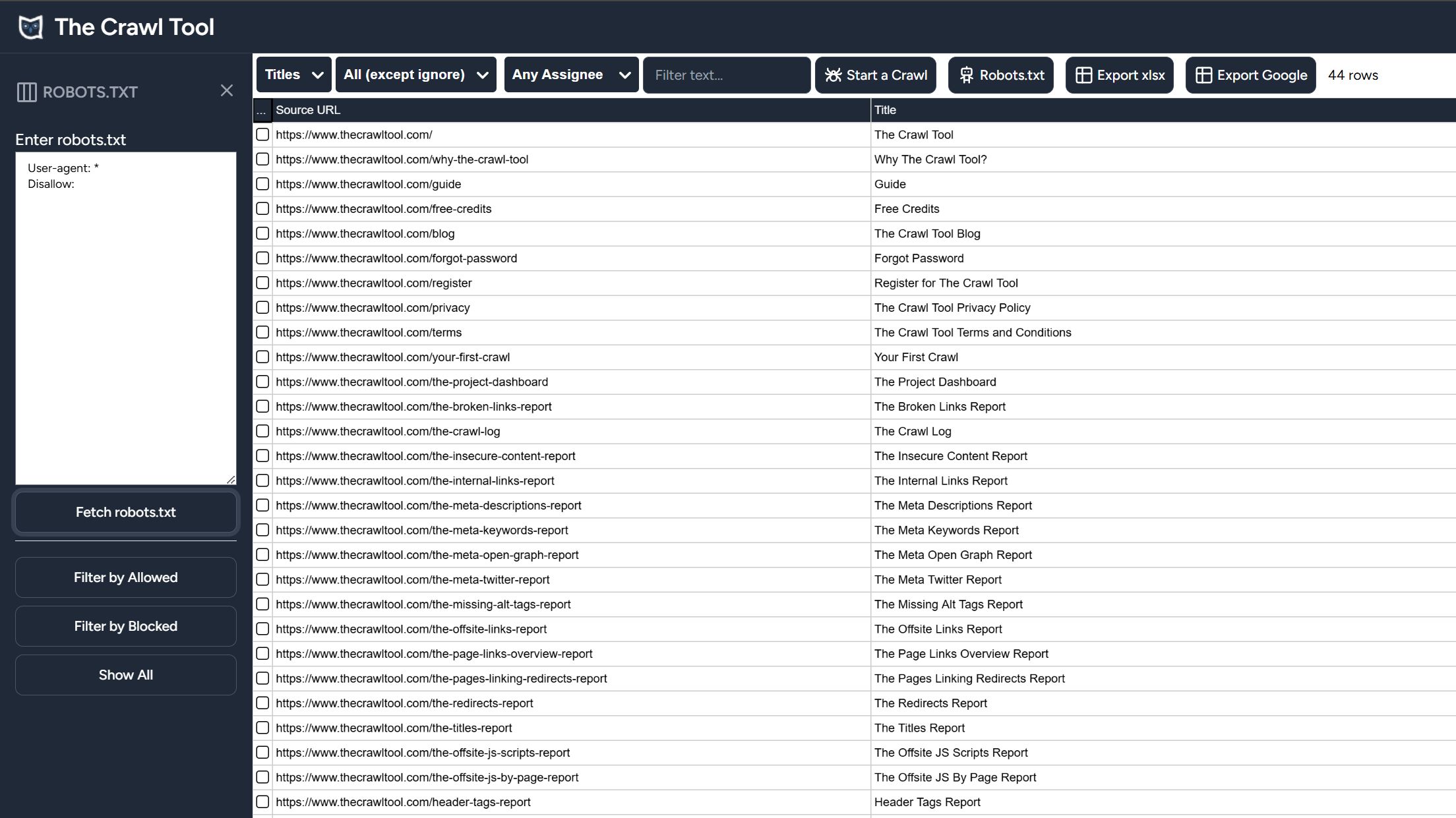
In The Crawl Tool now a "robots.txt" filter will appear in appropriate reports. This allows you to fetch the robots.txt file from the site, or type one in, and filter the reports by Allowed or Blocked pages.
This is a remarkably easy way to see what pages are blocked or not. We'd go as far as saying the best way. But it gets even better: because you can essentially test and view the results of any robots.txt file it provides the opportunity to modify the robots.txt file and to test and review what the results would be in a highly accurate way, before you risk changes to the actual robots.txt file in real life.
The absolute best way to use this technology is to sign up to The Crawl Tool, remember you get 1000 credits for FREE, and crawl your site.
Go to the reports and we'd suggest choosing the Titles report. Click the robots.txt button, and the "Fetch robots.txt" button, and your choice of "Filter by Allowed" or "Filter by Blocked". This way you're checking against your entire site worth of pages at once.
However, if you want to test just one url, then the form below will let you paste a robots.txt file against a url. It's useful for quick checks and to demonstrate our technology works. But again, to check multiple pages at once you're best off signing up for a FREE account.
Start with a free crawl of up to 1,000 URLs and get actionable insights today.
Try The Crawl Tool Free
Why experiment with Googlebot Beyond the fact it is interesting to understand how it works, it is potential useful if you ca...

LLMS.TXT again I've written about LLMS.TXT in the article about how getting one listed in an llms.txt directory mysteriously...

What's this about Adding Other Media to robots.txt I recently came across John Mueller's (a Google Search advocate) blog. I ...

Understanding the Importance of having a fast Mobile website I, personally, spend a lot of time focusing on site speed. The ...
What are robots.txt, sitemap.xml, and llms.txt These files are used by search engines and bots to discover content and to le...

AI Crawlers and Citing Sources The rise of AI, rather than search, crawlers visiting websites and "indexing" information is ...